
Google is the powerhouse of search so it’s alarming when you find out that your content isn’t indexed. Today you’ll learn how to check if you are indexed and fix any related issues.
—>>Build An Income-Generating Website That Lasts Decades!
>>Watch how I built my business step-by-step in a few minutes<<
—>>Earn online income for a lifetime.
>>Start Now<<
Wanting to check if your content is indexed has both a basic and an advanced use. For beginners, it’s simply wondering if they are doing everything right. Why build a website if Google won’t even put me in their search engine?
If that’s the case, checking your index status is simple.
For advanced users, knowing the number of pages you have indexed in search engine databases is an important way of ensuring that your website content is being crawled. A website can under perform in the SERPs due to crawlability issues that make it impossible for some your web pages to be indexed. With enough technical SEO issues like that, and you might be driving a car without all your cylinders firing.
- Answer: Search “site:mywebsite.com” in Google or look in Search Console
- What To Do If Your Content Isn’t Indexed
- How To Identify Crawl Issues
- Tips For Fixing Crawl Errors
- 1. Robots.txt
- 2. .htaccess File
- 3. Metadata
- 4. Sitemaps
- 5. Domain Name System (DNS) Errors
- 6. Pre-owned Domains
- 7. Spammy Plugins
- Final Word
Answer: Search “site:mywebsite.com” in Google or look in Search Console
Checking to see the number of indexed pages you have on Google or Bing is easy. All you have to do is use the “site:” search operator to see how many pages you’ve got on their index. A search parameter or operator is a string used to narrow the focus of particular search queries.
The “site:” directive provides a ballpark or estimated figure, so it may not be an exact number of pages but useful for uncovering problems. Enter the URL of your domain name using the directive without spaces like so: site:domain.com
The number of indexed web pages will appear at the top of the search results.
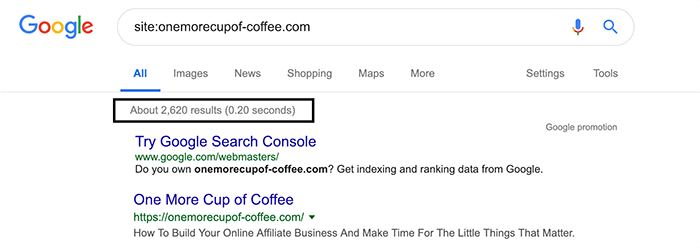
This is pretty accurate. I have 2500+ posts published, and a handful of pages
To examine a single content page, use the same search parameter to search for your page’s URL (with or without “http://”).

It’s also worth noting is that you shouldn’t use this as a measure of whether all your content is being crawled. Google can also index things like comment pages. For example, above you see that there are three comment pages that are indexed in Google for my “about me” page.
The other not-indexed page is not indexed page is because it was just published an hour ago, so I’m not worried about that.
Another way to use the “site:” search operator is to search for keywords on your site. Search for “site:mywebsite.com” and then your keyword. You’ll see what pages are indexed that contain that phrase, and is indexed if it appears on the SERP.

Keep in mind that it can take anywhere between four hours and 4 weeks for new content pages to be indexed, so checking to see if your page is indexed immediately after publishing an article is way too soon. If you publish regularly and are in the habit of sharing on social media, then you can get indexed and even ranked on page 1 in an hour or less. I’ve done it before!
What To Do If Your Content Isn’t Indexed
It’s common to run into problems that prevent search engines from crawling, indexing, and ranking your website pages. Often the reason why some of your pages are not being indexed is that you’ve made a technical error on your site, and you’re preventing search engines from crawling your site.
Having one or two pages that don’t get indexed isn’t an issue. The issue is when you are unaware of the problem, and a percentage of what you publish isn’t being indexed. If 25% of what you publish is literally seen by nobody, you’re wasting time, money and effort. You may be pulling out your hair wondering why traffic isn’t increasing, and it could be an easy fix!
One could go months or even years without ever noticing that they have crawlability issues. Typically, it’s easy to spot problems when your whole website isn’t showing up on the index, but when it’s just sections of the site, it can go unnoticed.
Additionally, you can use external tools to instantly check the number of indexed pages you have. The SEO Quake plugin for Chrome browsers can show you the total number of pages on the index for a given site. First, install the plugin. Navigate to any website and click on the SEO Quake logo to quickly see a wealth of data about it.
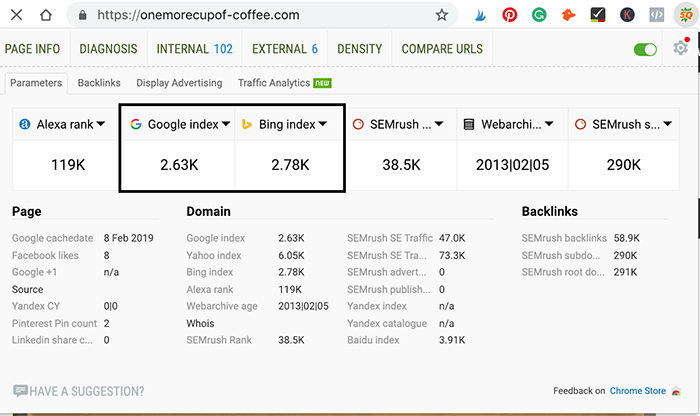
There are many browser plugins and addons like SEOQuake that can help you with your online business.
How To Identify Crawl Issues
Your number one friend here is going to be Google Search Console. If you don’t have that set up, get it set up immediately. Let the data stew for a bit, then see what Google has to say about your site. Checking out my stats, you can see that I have 73 errors right now. That sounds pretty bad!

If you dig deeper, you’ll see that the majority of errors are URLs I marked “noindex”. I’m not sure why Google is attempting to index them, since I clearly marked them as no-index. Regardless, I’m not worried about these errors because I don’t want these URLs indexed!
Looking at this page, I did discover two 404 errors I was unaware about. 404’s aren’t really a big issue though, so two pages out of almost three thousand is pretty good.
Furthermore, I can see that I have 17.4 thousand excluded page. What. Something is wrong.

Actually, it turns out none of these are a big deal. Digging in to the specific reasons, check out the following stuff on my site that’s excluded from search engines:
My tag pages are not indexed. WordPress does this by default since they are duplicate content anyway.

Next, we have some old AMP redirects. I had AMP installed for a while, but didn’t see any benefit and it was affecting my display ad RPM. So I removed the plugin, but then all my AMP URLs indexed in Google started turning up 404 errors. I had my host redirect all my old AMP URLs to the correct URL. This is something I might need to look into fixing, but since they point to the correct canonical page, it’s not a pressing issue at the moment.

Then, Google says that it’s crawling these “feed” URLs, but not indexing them. That’s fine. I don’t want them indexed. I don’t think I need to worry about this.

Lastly, I see a bunch of spammy links to my site linking to pages that don’t exist. Google is trying to crawl these pages because the spam sites are telling Google to do so, but those pages don’s exist, hence the 404 errors. I highly doubt this is a huge issue in Google’s eyes since this practice is so pervasive, but it’s something I might look into correcting if this is eating up some of my crawl budget.

Overall, looking in Search Console got me some insight into what Google sees on my website. Though there are some errors, none seem pressing. It looks like I don’t have any crawling issues and that all my pages are getting indexed properly. Some individual pages that gave me no-index warnings showed up, but they were very old, and irrelevant pages, so I’m glad Google de-indexed them!
Tips For Fixing Crawl Errors
Once you’ve identified that you probably have a problem, hop on over to Search Console and check for coverage errors. Look under the “Index” section located on the left navigation menu and select “Coverage”. Once there, you’ll see all the crawl errors you have and can begin addressing them (that’s the stuff from the screenshots above)
1. Robots.txt
This file holds directives that some search engine algorithms obey. The instructions contained within the robots.txt file tells AI how you want your website crawled, including any restrictions.
Your file may contain errors or directives that are preventing bots from crawling and indexing your web pages. Assess your file for errors or delete it if you’re ok with bots having access to your entire site.
2. .htaccess File
This file resides in Apache web servers and is another common reason why many sites face crawlability issues. Check your configurations for this file to ensure everything is in order.
For example, you may have redirect chains or loops that you aren’t aware of. Maybe your domain isn’t redirected to a preferred version (i.e. www.name.com to name.com).
3. Metadata
Ensure you’re not accidentally preventing some of your web pages from being indexed at the page-level using metadata. Specifically, the “noindex” directive, which communicates to bots that they shouldn’t index a given web page. You can change this setting on each page using your SEO plugin.
4. Sitemaps
This is a list of URLs on your website. It simplifies and speeds up indexing time since bots can crawl one page to access all your content. However, you can run into problems when your sitemap isn’t up to date.
With WordPress, you can use your SEO plugin, or you can use a separate plugin like XML Sitemaps (this is what I use).
5. Domain Name System (DNS) Errors
DNS is a naming system for computers, servers or other systems connected to the Internet. Think of it as a phonebook that translates domain names into IP addresses on the back-end. That’s why you can type “onemorecupof-coffee.com” into your browser and access all the content on this site, which by the way, is located on a server.
Issues with SEO can arise when an improper configuration is used to create your DNS records. For example, the A record directs all incoming traffic to your domain’s server. You’ll halt all incoming traffic if the wrong IP address to your server is used because no system will be able to reach your site. Plus search engines will demote or de-index your web pages once enough people click the back button to exit your site.
This pretty technical, so if you run through all the “easy” solutions above, contact your host and see if they can provide any insight.
6. Pre-owned Domains
Domain names normally come with the previous history when you buy them from someone else. Search engines have been known to penalize websites for spammy or shady practices. Most of these sites go out of business and in an attempt to salvage what’s left, they’ll often sell their domain names.
“Aged” domains are pretty popular as a way to gain instant authority in Google (due to the link profile), but if the links are spammy, that aged domain you just bought for a pretty penny might be working against you.
7. Spammy Plugins
A lesser-known problem that I ran into one time was fighting against a spammy plugin. I bought a “premade website” on Flippa for $300, and it came with an Amazon product aggregator. It would basically scrape products and descriptions from Amazon, and turn my site into a showcase for products related to my niche. I thought it was an interesting idea to try out, and if I could use typical SEO practices to my blog, I could rank and earn easy money from Amazon.
Well, it turns out Google doesn’t like all that duplicate content! Google would not index my 100% original blog posts for many months, so I assume it was the plugin’s problem. I deleted the plugin, redirected the content to a new domain, and the issue went away within three weeks.
Final Word
You shouldn’t worry too much about how quickly your new web pages get indexed by Google or Bing. However, definitely keep an eye on your crawl coverage in GSC! Want to get your stuff indexed faster? Use “Fetch” in Search Console to alert Google about your new content. You can also share on Twitter and Facebook to send some crawl bots to those pages and get them indexed faster.
What’s up ladies and dudes! Great to finally meet you, and I hope you enjoyed this post. Sign up for my #1 recommended training course and learn how to start your business for FREE!